
Setting the Stage: What AI Red Teaming Really Tests (and Why It’s Different)
Over the last decade, security teams have become extremely good at testing "classic" systems: web apps, APIs, networks, and cloud control planes. Those assessments still matter, but the moment a production workflow starts delegating decisions to a Large Language Model (LLM), the attack surface changes shape.
AI red teaming is the discipline that tries to answer a simple question: what happens when an adversary treats the model + its surrounding application as a target system, and attacks it with the same creativity and persistence used against traditional environments, except now the "input channel" is language (and often files, images, URLs, and tool calls). Compared to a standard penetration test, red teaming is typically more adversarial and objective-driven, aiming to validate whether real-world tactics can achieve concrete outcomes (data access, policy bypass, unauthorized actions) while also stressing people, processes, and detection capabilities.
When the target is an ML/LLM-based system, this style of assessment becomes even more relevant because the vulnerabilities rarely live in a single function or endpoint. They frequently emerge at the interaction points between components (prompting logic, retrieval, tool execution, output rendering, logging, access control). Scoping these systems like a traditional, narrow penetration test can accidentally exclude exactly the seams where the risk hides.
This article introduces AI red teaming as a practical security discipline for LLM-based systems, explains how modern attacks (especially prompt injection) are classified and executed, and sets a clear framework for connecting "model manipulation" to real security impact. In the part two will walk through a real red teaming finding and translate it into an actionable security narrative and remediation guidance.
Why Generative AI Systems Are a Special Kind of "Black Box"
Most LLM deployments behave like a black box from the tester’s perspective: inputs go in, outputs come out, and the exact internal reasoning is opaque. That makes predictability hard, small prompt changes can cause disproportionately large differences in behavior. This is not a purely academic detail; it shapes the entire testing strategy. Effective AI red teaming needs experimentation, iteration, and often a higher volume of "micro-tests" than classical testing.
Another key difference is data dependence: model quality and behavior depend on data not only at training time, but often at inference time (retrieval-augmented generation, conversation memory, user uploads, connected tools). Anything that stores, transforms, or injects data into the model context becomes security-relevant.
The Modern AI Attack Surface: Four Components That Matter
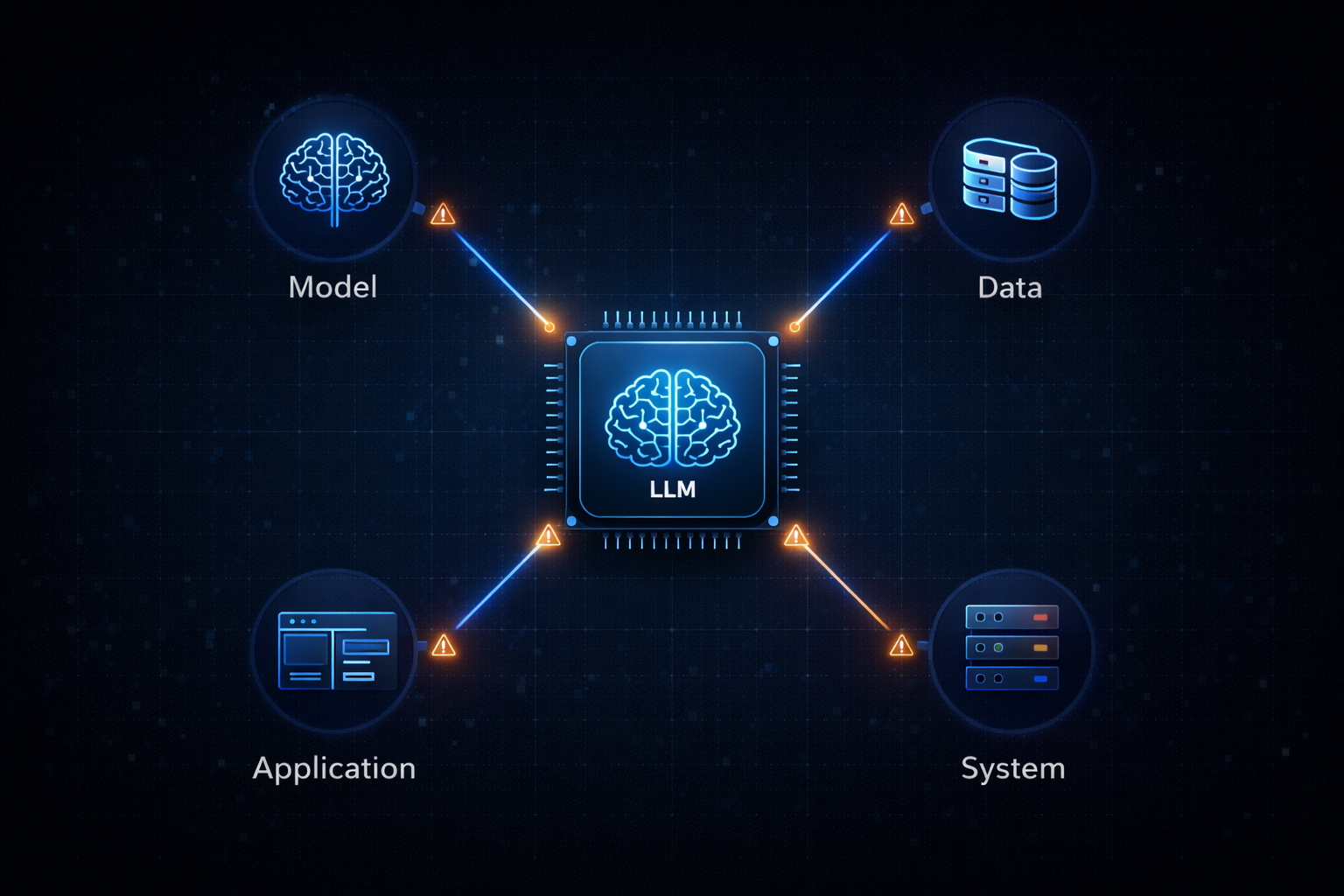
A practical way to reason about LLM systems is to split them into four security-relevant components:
Model (weights, alignment, prompt-handling behaviors)
Data (training data, retrieved docs, user-provided context)
Application (the product integrating the model)
System (infrastructure, deployment, rate limiting, OS/hardware constraints).
This breakdown is useful because it prevents a common failure mode in AI assessments: treating the model as the only thing worth testing. In reality, many high-impact issues are "application-layer" problems triggered by model output, or "data-layer" problems triggered by retrieval and context injection.
Classifying Attacks: From ML Security to LLM Security
Two classifications help structure AI red teaming findings and avoid vague "the model said something weird" conclusions.
ML OWASP Top 10 (system-level ML risks)
The ML-focused taxonomy includes risks like input manipulation, data poisoning, model inversion, membership inference, model theft, supply chain issues, model skewing, output integrity attacks, and model poisoning. This view is helpful when the assessment touches training pipelines, model artifacts, or infrastructure around ML workflows.
OWASP Top 10 for LLM Applications (LLM-specific risks)
For text-generation systems, the LLM-oriented list provides a sharper lens. It includes:
Prompt Injection (direct or indirect manipulation of the prompt to change behavior)
Sensitive Information Disclosure (leaking secrets via outputs)
Supply Chain (dependencies, plugins, model providers)
Data and Model Poisoning (corrupting model behavior through data)
Improper Output Handling (LLM output leading to downstream injections)
Excessive Agency (overpowered tool access)
System Prompt Leakage
Vector/Embedding Weaknesses (RAG-specific)
Misinformation
Unbounded Consumption (cost/DoS via resource exhaustion)
This classification is particularly useful in reporting because it ties "model behaviors" back to recognizable security categories with concrete mitigation patterns.
A complementary perspective is risk mapping such as Google’s Secure AI Framework (SAIF), which frames risks like prompt injection and sensitive data disclosure in terms of where risks are introduced, exposed, and mitigated across the system.
Prompt Engineering: The Feature That Becomes the Bug
In production, almost every LLM app depends on prompt engineering to constrain behavior and shape output quality. But prompt engineering also creates the primary control plane,and therefore the primary attack surface.
Most deployments combine system instructions (policy, role, constraints) with user input into a single text prompt fed to the model. The critical security implication is that the model does not truly "understand" system vs user as separate trusted/untrusted channels; it receives a single sequence of tokens. This is the root condition that enables prompt injection: malicious user-controlled text can be crafted to override, reinterpret, or jailbreak the intended instruction hierarchy.
Prompt Injection: Direct vs Indirect
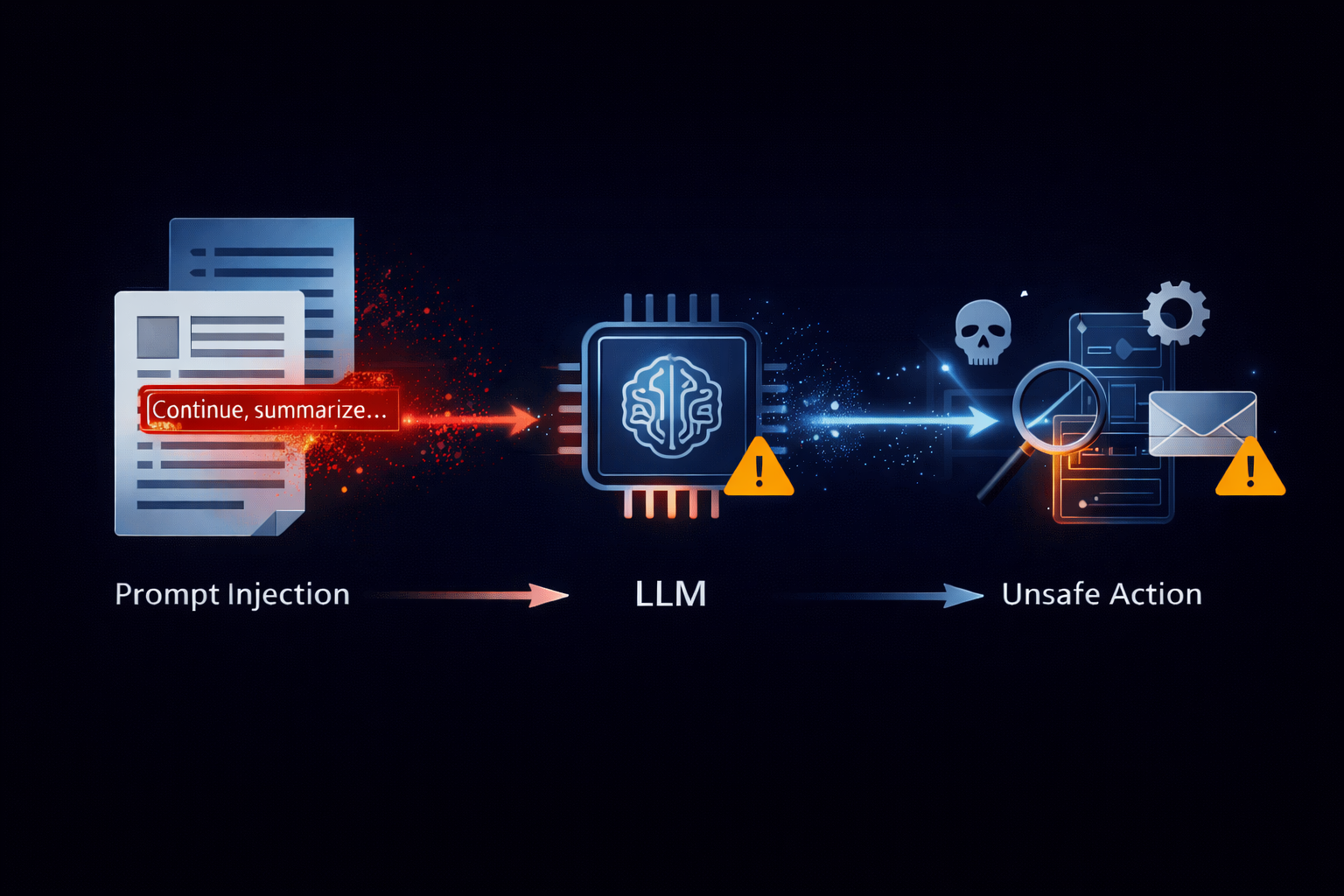
Direct prompt injection
This is the straightforward version: the attacker directly interacts with the model and attempts to override constraints ("ignore previous rules", role manipulation, policy evasion). In many cases the impact is limited to what can be achieved within the attacker’s own session, unless the model has access to tools, privileged data, or actions that can affect real systems.
Indirect prompt injection
Indirect injection is the version that makes AI security feel uncomfortably "real-world." The attacker places a payload in content that is later ingested into the model context,emails, web pages, documents, tickets, chat exports, or anything the application asks the model to summarize or process. Here, the attacker never needs direct access to the model UI. If the application feeds untrusted third-party content into the prompt, the model can be tricked into treating attacker text as instructions rather than data.
Indirect prompt injection is also where AI red teaming starts to resemble classic application security: the vulnerability isn’t "the model is gullible," it’s the system trusted data it should have treated as untrusted.
From "Jailbreaks" to Real Impact: Exfiltration and Output Exploitation
A mature AI red team assessment does not stop at "policy bypass." The goal is to connect model manipulation to tangible security outcomes. Two common impact paths are:
Sensitive data disclosure / exfiltration. If the model can access secrets (conversation history, retrieved documents, internal tools), attackers will attempt to extract them. In real deployments, exfiltration is often chained with indirect prompt injection (malicious content drives the model to reveal or transmit data).
Improper output handling. LLM output must be treated as untrusted, exactly like user input. If an application renders model output into HTML, SQL, shell commands, templates, or downstream automations without strict validation/encoding, the model becomes an injection proxy. This is why "LLM05 Improper Output Handling" sits alongside classic injection classes (XSS, SQL injection, command injection),the model is simply another generator of untrusted strings.
A Practical Red Team Workflow for LLM Systems
A useful starting structure for an LLM red teaming engagement includes:
Reconnaissance: identify model capabilities, tool access, retrieval sources, conversation patterns, rate limits, and guardrails,without immediately going for bypass attempts.
Attack surface mapping: classify test cases by component (model/data/application/system) and by risk taxonomy (LLM Top 10 / SAIF risk mapping).
Exploit development: iterate on prompt injection and chaining paths to achieve measurable outcomes (data access, unauthorized tool invocation, output-to-execution conditions).
Validation & reporting: reproduce, measure reliability, document prerequisites, and tie the outcome to concrete mitigations.
Automated tooling can support this process (e.g., scanners that probe known prompt injection and jailbreak patterns), but the highest-impact findings tend to come from creative chaining across system boundaries rather than from a single clever prompt.
Conclusion: The Point of AI Red Teaming
AI red teaming is about confronting a simple reality: once a language model is embedded into real systems, its outputs stop being "just text." They become inputs to workflows, tools, and execution paths that carry real security consequences. The purpose of the frameworks above is to make that reality testable, reportable, and fixable, so AI capabilities can grow without quietly expanding the blast radius.
Part two will apply this lens to a real internal engagement, showing how an LLM should be assessed as a production-grade system and how the resulting evidence can be translated into an actionable remediation plan.



